みなさん、こんにちは
本日投稿の内容について、以前別サイトで私が投稿したブログの内容です。
サイトの閉鎖に伴い、こちらで再度掲載いたします。
本日はNutanixの基本的な概念である、Nutanixの構成要素についてご紹介したいと思います。
Nutanixを覚えようとする人は、Nutanix Bibleなどを読まれるかと思いますが、こちらの内容も是非参考にして頂ければと思います。
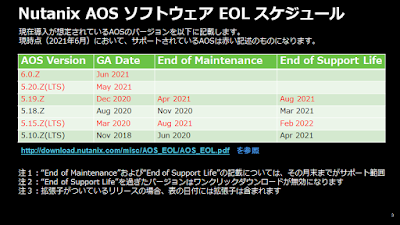
1.Nutanixの用語について

Nutanixを構成する⽤語ついて、上記のイメージのようなものがございます。
それぞれの用語について説明していきたいと思います。
- ノード
ノードはNutanixクラスタの基本単位になります。各ノードは標準ハイパー バイザー
を実行し、SSDとHDDストレージの両方で構成されたプロセッサー、メモリおよび
ローカルストレージを含むます
- ブロック
ブロックは最⼤4つのノードを含むNutanixラックマウント型ユニットです。
(2U4Nodesの⾼密度サーバーが対象になります)
- クラスタ
クラスタはAcropolis Distributed Storage Fabric(DSF)を形成するNutanixブロックと
ノードのセットです。
- データストア
データストアは仮想マシン操作に必要なファイル論理コンテナです。
- vDisk
vDiskは仮想マシンにストレージを提供するコンテナ内の使⽤可能なストレージの
サブセットです。コンテナがNFSボリュームとしてマウントされている場合、その
コンテナー内のvDiskの作成および管理はクラスターによって⾃動的に処理されます。
- コンテナ
コンテナはストレージプールの論理的なセグメンテーションで、仮想マシンまたは
ファイルのグループ(vDisk)を含みます。コンテナは通常、NFSデータストアまたは
SMB共有の形式で共有ストレージとしてホストにマッピングされます。
- ストレージプール
ストレージプールとは、クラスタ⽤のSSDやHDDなどの物理ストレージデバイスの
グループです。ストレージプールは複数のNutanixノードにまたがることができ、
クラスターの規模が拡⼤するにつれて拡張されます。
- ストレージティア
ストレージティアでは、MapReduce階層化テクノロジーを利用して、データを最適な
ストレージ階層(フラッシュまたはHDD)にインテリジェントに配置し、最速の
パフォーマンスを実現します。
- ラック(フォールトトレランス)
ノード/ブロックをもう少し拡張したラック(フォールトトレランス)という概念も
あります。

ラックの耐障害性により、データの冗長コピーが作成され同じラック内にないノードへ配置されます。ラックフォールトトレランス機能が有効になっている場合、クラスタはラック認識機能を備えており、1つのRack(RF2)または2つのRack(RF3)の障害でゲストVMを稼働させ続けることができます。
1つのRackに障害が発生すると、ゲストVMデータとメタデータの冗長コピーが他のRackでも存在します。
2.ノードについて

仮想マシンのホストのことを指しますが、Nutanixは通常のラックサーバと⾼密度のサーバーで構成されるため、それぞれのハードウェアでわかりやすく⽰してみました。⾼密度サーバーでは、筐体の中に収納されている⼀台のサーバーになります。
また、クラスタの基本単位はNutanixノードです。クラスタ内の各ノードは業界標準のハイパーバイザーを実行する標準x86サーバーで、低遅延SSDと経済的なHDDの両方で構成されるNutanixコントローラVM、プロセッサ、メモリ、およびローカルストレージを含みます。ノードは10GbEネットワークを介して連携して、NutanixクラスターとAcropolis Distributed Storage Fabric(DSF)と呼ばれる分散プラットフォームを形成します。
3.ブロック・クラスタについて

ブロックについては先に説明した通り、⾼密度サーバーのみに適応される概念です。4ノードを⼀つのブロックとして扱います。もちろん、筐体障害の場合はシステム停⽌になったりします。そこで、複数の筐体にまたがってデータを格納する⽅式(Block Awareness)を採⽤することが多いです。
4.Prism上での画面イメージ

Prism上からの画⾯で説明します。ハードウェアのメニューからDiagramを選択するとNutanixのクラスタを形成しているハードウェアが表⽰されます。(今回は2U4Nodeの筐体に3台分しか表⽰されておりませんが)
今回の構成では、クラスタとブロックが同じ枠で囲われておりますが、ノード数が多ければクラスタは組んでいる構成で表⽰されます。
⻘⾊で表⽰されているところはDiskになりますが、コンポーネントに障害が起きていれば、該当のパーツが⾚く表⽰されます。
5.Distributed Storage Fabric

Nutanixのノードがグループとなって、分散ストレージファブリックを形成されます。この分散ストレージがハイパーバイザーを動作させる基盤になり、またI/Oはローカルで処理された後に、データの冗⻑化を保つためにデータを分散配置します。
6.データの構造

DSFのデータ構造はこのようなイメージで構成されます。物理ディスクグループのストレージプールを作成され全体の容量が定義されます。そこからコンテナを定義して使⽤可能な領域を定義して、コンテナ内にvDisk(仮想マシン⽤の領域)を割り当てます。こちらについては、ハイパーバイザーによって、サポートするプロトコルも異なりますので、ご注意下さい。AHVについてはiSCSIになります。

ストレージについて画⾯イメージをこちらに載せておきます。ストレージメニューからTableを選択します。ストレージプールを選択すると、テーブル情報とサマリ情報が表⽰されます。こちらで、ストレージプールやコンテナの情報が確認できます。また、データをExportすることもできます。
以上で、Nutanixの構成要素の説明を終わります。
よろしくお願いします。